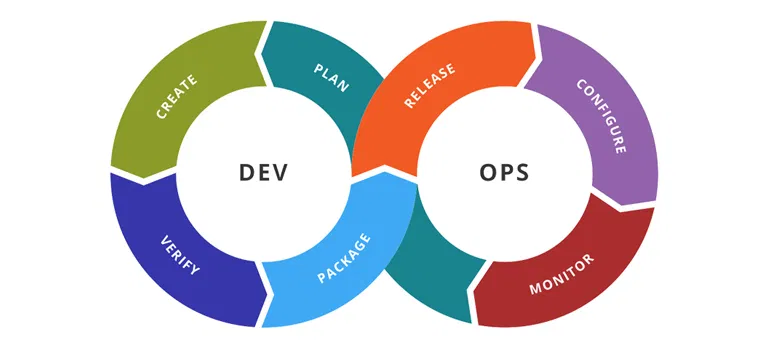
CLOUD & DEVOPS
Cloud Infrastructure That Just Works
Expert cloud operations support for AWS, Azure, and Google Cloud. 24×7 monitoring, reliability engineering, cost optimization, and infrastructure management that keeps your applications running smoothly.